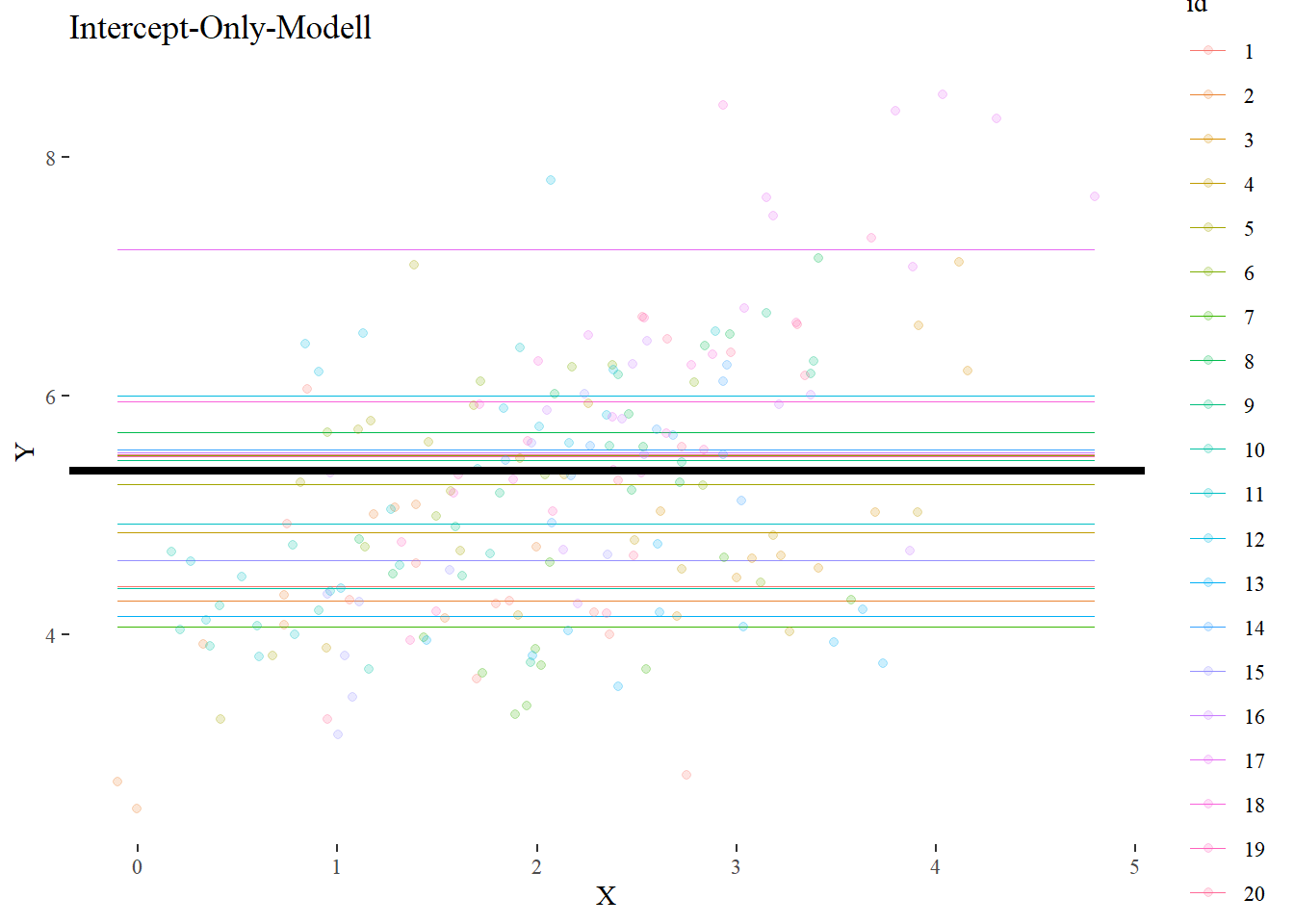
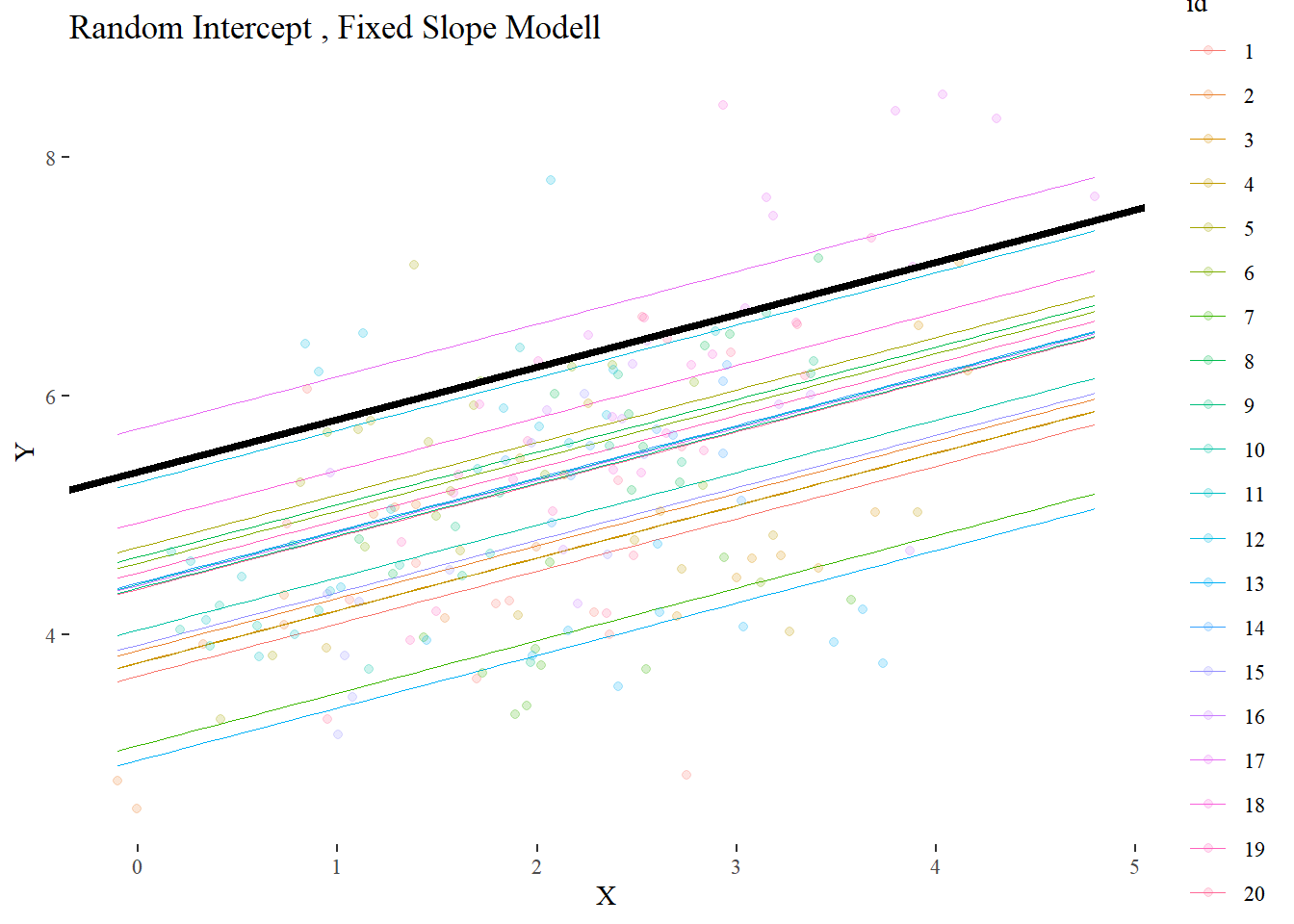
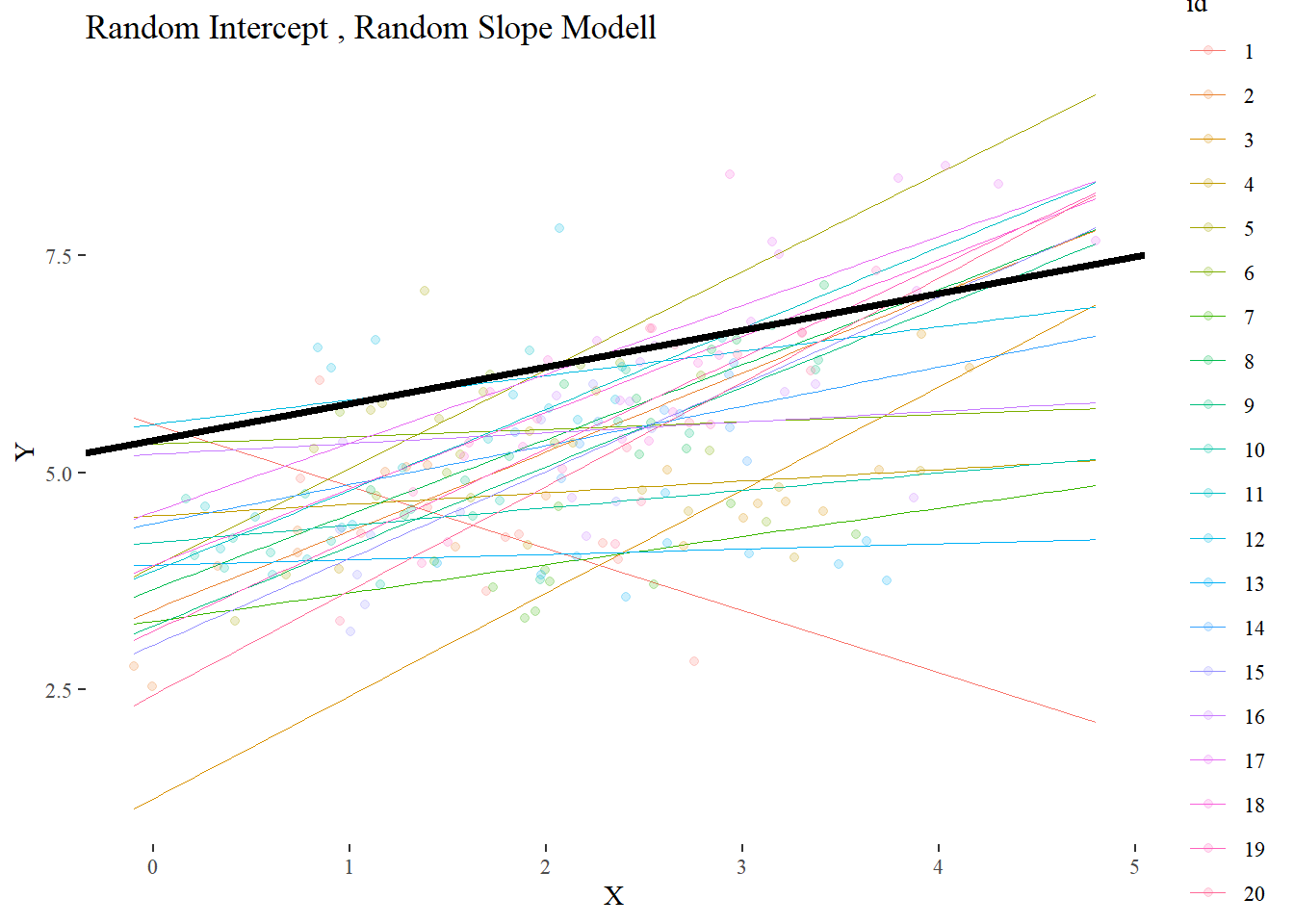
Für diese Einheit verwenden wir den folgenden Datensatz (data.frame/tibble):
df_example1: Alle Skalenscores im Long Format, mit personen-zentrierten Variablenvarianten (“_dm”) und Personen-Mittelwerten der täglich gemessenenen Variablen (“_gm”). Struktur des Datensatzes kann man sich ansehen mit head() oder print().
head(df_example1)
id
y
m
x
y_dm
m_dm
x_dm
y_gm
m_gm
x_gm
1
4.003538
4.769391
2.365486
-0.3020232
0.8945291
0.6845636
4.305561
3.874862
1.680922
1
4.925174
2.510943
0.748855
0.6196128
-1.3639189
-0.9320674
4.305561
3.874862
1.680922
1
4.598564
3.098112
1.395041
0.2930028
-0.7767499
-0.2858814
4.305561
3.874862
1.680922
1
4.286179
4.610746
1.860026
-0.0193822
0.7358841
0.1791036
4.305561
3.874862
1.680922
1
4.183494
4.549044
2.288019
-0.1220672
0.6741821
0.6070966
4.305561
3.874862
1.680922
1
3.631716
3.590049
1.696510
-0.6738452
-0.2848129
0.0155876
4.305561
3.874862
1.680922
Im Folgenden betrachten wir ein Modell in dem y durch x vorhergesagt wird.
4.3 Random Intercept Modell / Null-Model
Die Funktion lmer() benötigt zwei Argumente, (a) die Formel und (b) den Datensatz. Zum Aufbau und Details der Formeln s. Folien.
Zur Ansicht der Ergebnisse haben wir zwei Optionen: Den summary() Befehl - die Standardansicht, wie von den Paketautoren implementiert, den tidy() Befehl aus dem broom-Package, und den model_parameters() Befehl aus dem parameters Package. tidy() und model_parameters() Funktionsoutputs könnten nach Excel/Word exportiert werden mittels der write_xlsx() Funktion, oder indem das Notebook als .docx “gerendert” (ausgegeben) wird.
summary(nullmodel)
Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: y ~ (1 | id)
Data: df_example1
REML criterion at convergence: 2742.9
Scaled residuals:
Min 1Q Median 3Q Max
-6.1492 -0.5420 -0.0369 0.5543 4.6493
Random effects:
Groups Name Variance Std.Dev.
id (Intercept) 0.6902 0.8308
Residual 0.7164 0.8464
Number of obs: 1000, groups: id, 100
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 5.36755 0.08728 99.00000 61.5 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
tidy(nullmodel)
effect
group
term
estimate
std.error
statistic
df
p.value
fixed
NA
(Intercept)
5.3675530
0.0872832
61.49586
99
0
ran_pars
id
sd__(Intercept)
0.8307776
NA
NA
NA
NA
ran_pars
Residual
sd__Observation
0.8464254
NA
NA
NA
NA
model_parameters(nullmodel) |>print_html()
Model Summary
Parameter
Coefficient
SE
95% CI
t(997)
p
Fixed Effects
(Intercept)
5.37
0.09
(5.20, 5.54)
61.50
< .001
Random Effects
SD (Intercept: id)
0.83
SD (Residual)
0.85
Im Seminar verwenden wir den Output von model_parameters(), weil er eine recht gut formatierte Übersicht gibt.
4.3.1 ICC
Aus dem Null-Model wird der ICC bestimmt. Dies haben wir in der vorhergehenden
ICC: \(\frac{\tau_{00}}{\tau_{00}+\tau_{ij}}\), \(\tau\) gibt die Varianz des jewiligen Koeffizienten an.
Wir können dies aus dem Modelloutput nehmen und berechnen:
Als nächstes fügen wir einen Level-2 Prädiktor hinzu, der pro Person nur einmal gemessen wurde. Dabei handelt es sich für gewöhnlich um (1) Variablen, bei denen wir nicht an täglichen Schwankungen interessiert sind, wie soziodemografischen oder Persönlichkeitsvariablen, oder (2) den Mittelwert der Personen auf einer täglich gemessenen Variable. Im Beispiel verwenden wir (2), “x_gm”.
Wir arbeiten in der Übung mit einem neuen Datensatz.
Mache dich mit ihm vertraut. Diesmal benutzen wir einen Datensatz in dem die Variablen “labelled” sind, also Beschriftungen haben. Wir können die Labels mit get_label() oder view_df() abrufen.
Teste zunächst ein Random intercept, fixed slope Modell, und dann ein Random Intercept, Random Slope Modell. Urteile, ob die Hypothese angenommen oder verworfen werden sollten.
Die Hypothese 1 kann angenommen werden, da der Effekt von illegitimen Aufgaben (illtask_dm) signifikant positiv ist. Auch im strengeren random Slopes Modell ist der Effekt weiterhin signifikant.
Wir können auch sehen, dass im Random Slopes Modell die Konfidenzintervalle etwas breiter sind und der Standardfehler etwas grösser sind als im Fixed Slopes Modell. In Random Slopes Modellen können die Regressionskoeffizienten zwischen den Individuen variieren, was zusätzliche Varianz in die Schätzungen einbringt. Diese zusätzliche Unsicherheit führt dazu, dass sowohl die Standardfehler als auch die Konfidenzintervalle grösser ausfallen als in Fixed Slopes Modellen, bei denen die Steigung als konstant über alle Gruppen angenommen wird. Dadurch reflektieren die größeren Intervalle die höhere Unsicherheit in der Modellierung individueller Unterschiede in den Effekten.